If anyone else is down for some command line JSON munging this little tool knocked my socks of this week: stedolan.github.io/jq/
IT’S ALIVE!
YESSSSSSSSSS I FUCKING MADE YOOUUUUUUU. I AM INVINCIBLE!

Almost there!

Dispatch your S3 methods off global state like a real crusty wrangler #rstats
Here’s a fun #rstats one from last week:
At my work, we’ve wrapped our database queries for our core datasets in an R package. Last week I needed to implement a second backend for that package such that the same interface could be used to issue fetches against either:
- an on premises Microsoft SQL Server
- a set of parquet files stored in AWS S3.
The idea being that pipelines that we author on our local machines should just work when running on AWS with zero changes to code. We’ll use an environment variable to control which backend our data getting functions target. So:
Sys.getenv("QFESDATA_BACKEND") == "analytics"means hit the SQL severSys.getenv("QFESDATA_BACKEND") == "aws"means slurp those parquet files
So how to implement switching which methods are dispatched based on an environment variable? Well I definitely don’t want this:
get_oms_responses <- function() {
if (Sys.getenv("QFESDATA_BACKEND") == "analytics") {
... SQL DB stuff
} else if (Sys.getenv("QFESDATA_BACKEND") == "aws") {
... AWS stuff
}
... common stuff
}
You CAN do that and it will work. But now the different logic for the two backends is kind of tangled together. Say I want to add a different backend in the future, I can’t do that in a way that doesn’t interact with code that is already known to work. Regressions could easily be introduced.
Isolation is what I wanted. The first thing I thought of was S3 methods, since this a bread and butter issue that S3 is designed to solve. But I thought to myself: “If I use S3 I’ll have to change the interface of my functions to refer to an object to be dispatched off.” And I didn’t like that. In other words, this type of thing:
get_oms_responses <- function(backend = "analytics", ...) UseMethod("get_oms_responses", backend)
I’d have to change all the documentation for all the functions to explain the backend arg.
So I went and implemented some complicated metaprogramming thing that detected the method you were calling and recalled a new method with the same arguments pulled from the correct parent environments based on Sys.getenv("QFESDATA_BACKEND"). I felt really smart, but the code was hard to follow, and I had to write a bunch of unit tests to convince myself it worked.
What happened next was that on seeing the code, my colleague, Anthony North, pointed out that S3 method dispatch doesn’t need to dispatch off one of the generic function arguments, it can use any object!
E.g.
get_oms_responses <- function(backend = "analytics", ...) UseMethod("get_oms_responses", ANYTHING_YOU_WANT_BUCKO)
Or perhaps more pertinently:
get_qfes_backend <- function() {
backend <- Sys.getenv("QFESDATA_BACKEND")
structure(backend, class = backend)
}
get_oms_responses() UseMethod("get_oms_responses", get_qfes_backend())
get_oms_responses.analytics <- function() {
... SQL server stuff
}
get_oms_responses.aws <- function() {
... AWS stuff
}
I immediately deleted what I had written and switched to this approach. Scary metaprogramming was gone, and I don’t need to unit test S3 method dispatch. It’s working perfectly.
Upon close reading of the S3 documentation, it appears this usecase is covered, barely:
for ‘UseMethod’: an object whose class will determine the method to be dispatched. Defaults to the first argument of the enclosing function.
But I’ve never seen the convenience of using any old object outside the generic function’s arguments discussed before. Quite a handy one!

Today I participated in the first meeting of the #rstats RConsortium working group for R repositories. The path I started on with cranchange lead me to this point, although this group has a much larger scope.
On the CRAN side of things I was encouraged to hear from Michael Lawrence that there is a desire to make change at CRAN including plans create a more informative public web presence, and bring on someone in a Developer Advocate role(!).
One thing I think that is going to be key to positive change is eliciting some clearer sense from CRAN as to what the group’s goals and priories are. For example: What priority is placed on being a Continuous Integration service for R-Core vs a validation and distribution mechanism for a rolling release of R packages?
I have a hunch that some of the inconsistency R users and developers see is due to tension between these types of objectives, but I am keen to learn more from this group.
I am very thankful to the Linux Foundation and RConsortium for facilitating this group, especially Joseph Rickert for leading.
Hadley Wickham’s meeting minutes are accessible from the repository
Ice and fire vibes #notGenerative
Made with #rstats {rdeck}
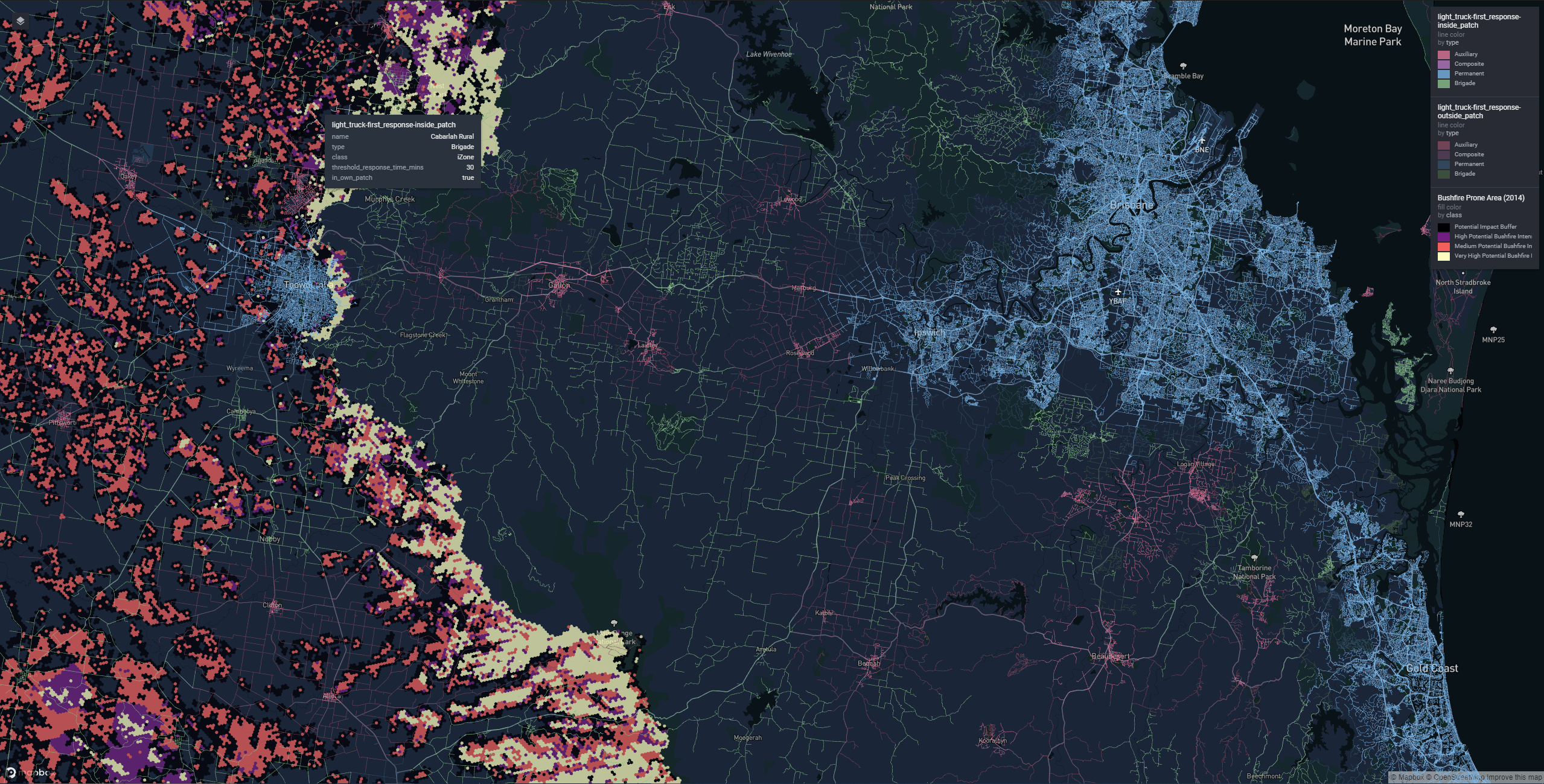
Project filled weekend! I give you Saturday and Sunday.
😅😴


#rstats VSCode productivity tip: assign keybindings to workbench.action.terminal.scrollDown and workbench.action.terminal.scrollUp so you can move though console output without having to switch back and forth from the terminal or use your mouse.
When you take advantage of {dplyr} groups for mutating or filtering you DON’T get the helpful warning about sticky groups as per summarise(). This red flag I put into {paint} has saved me twice in 2 days! #rstats
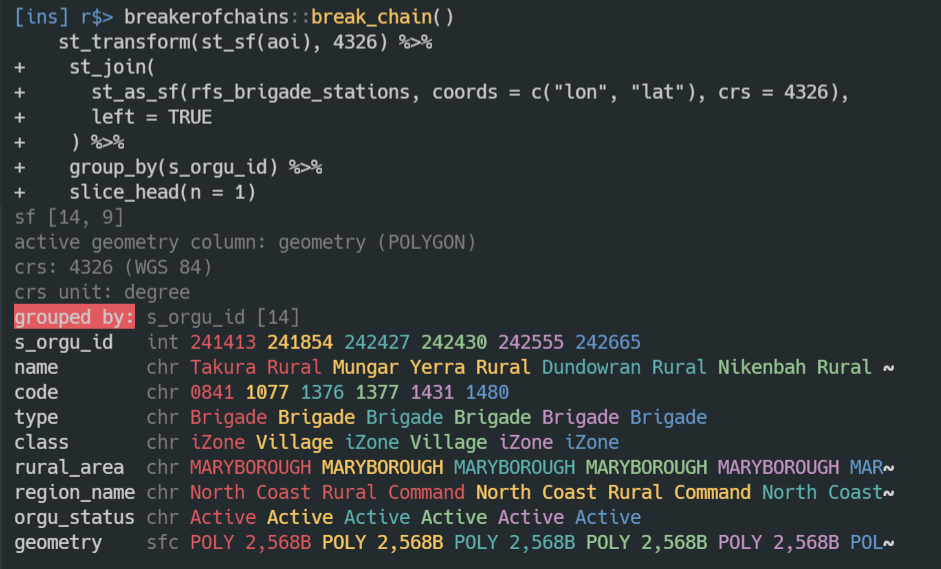
New project! Let’s get busy!

New in {rmdocs} 0.2.0:
You get an Rmd verison of the dev help for your package when it detects {devtools} is loaded. #rstats
Something in prod bombed over the weekend. I had logged the #rstats {targets} build output so I knew which target. I pulled the dependencies from the cache stepped through the target code interactively until I found the bomb. Data source schema change ofcourse. Took about ~10 minutes to pin down the field and record in the cached data and fire off the email to upsream team. Prod without a target graph and a cache? I can’t even.
Setup
In response to a Twitter question from Jared Lander, here is my logging setup:
Top level file is a .cmd - yes we’re on Windows Server Data Centre.
pushd $~dp0
Rscript.exe the_script.R > log.txt 2>&1
Roughly translated to:
- set the working dir to the scipt’s location.
- pipe the std output and std error of running the_script.R to log.txt
Here is the_script.R:
capsule::run({
targets::tar_invalidate(source_file)
targets::tar_make(output)
})
Which translates to:
- within my {capsule} ({renv}):
- invalidate the source data (so it will be refreshed)
- build the output (this plan has multiple outputs on different schedules)
To do interactive diagnostics with cached targets, I run capusle::repl() to switch my R REPL over to the capsule environment.
After 7 days of dogfooding, the addition of a test suite, documentation, and 1 confirmed user, {paint} is now v0.1.0 #rstats
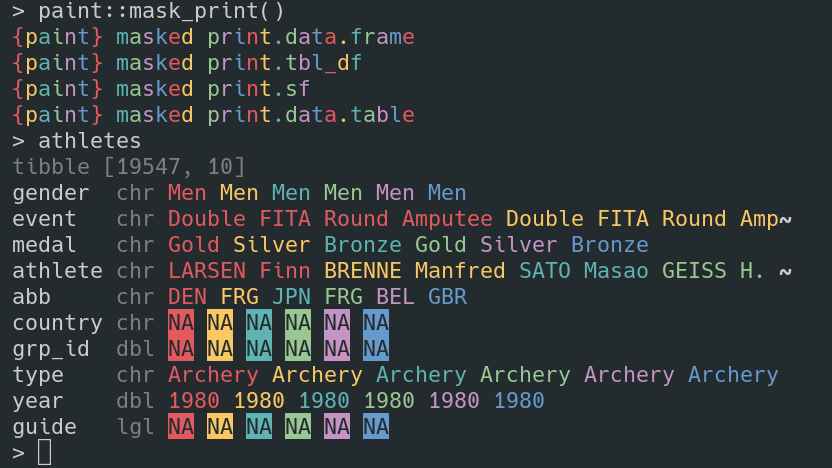
Happy Friday #rstats! This week’s diversion is alternative print() methods for data rectangles. Here’s {paint}, highly experimental, works on my machine stage:
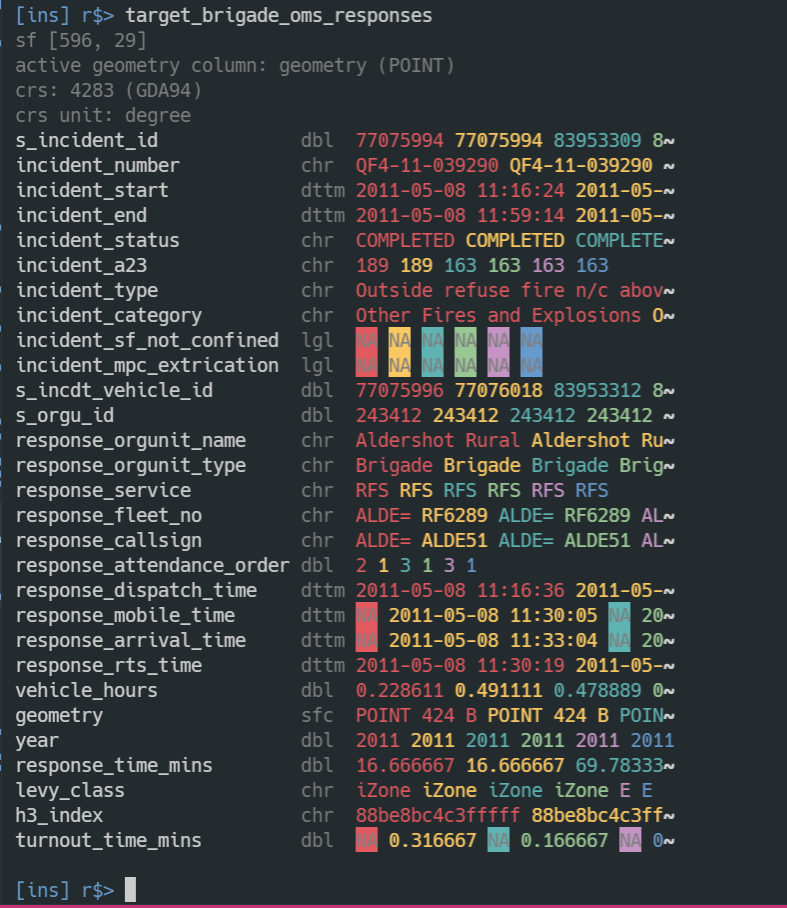
Bit of a scraping project on that’s going to sip thousands of xml files over the next couple of days. Using #rstats {targets} dynamic branching each xml file is a cached target. The advantage of this is that if the process is interrupted at any time for any reason it can be resumed with a simple tar_make(). Niiiiiiice.
Happy Friday #rstats! Incited by @mdsumner {rmdocs} now provides replacements for utils::help and utils::?, so you never have to accidently look at HTML help again.
New {targets} addin: tflow::rs_load_current_editor_targets(). Load targets from cache that are referred to in the code you are looking at. #rstats
Happy Friday {rmdocs} now handles namespaced::symbols #rstats
If you run the addin with the cursor on withr::with_options you’ll get served some delicious Rmd help for that function, even if you had rlang::with_options masking it via library(rlang).
Unlocking fast #rstats lockfile generation
This week I cracked a problem that I’d been stewing on for a while: Fast generation of renv.lock files.
For those not in the know: These fully describe an R project’s package dependencies and can be used to create a “known good” package environment for the project to run in. You should definitely be using these! Typically these are created with {renv}.
I set myself a budget of 3 seconds to:
- Detect my project dependencies
- Read package metadata
- Determine a full set of recursive dependencies
- Write a lock file readable by
{renv}
My thinking was that this amount of time is short enough to facilitate new workflows involving always-on automated lockfile generation. So instead of lockfile creation being a kind of manual discipline that is done interactively, it can become something that just automatically happens everytime you build a pipeline with {targets} or render a document with {rmarkdown}.
And that means people won’t forget to do it before they go on holiday, Murhpy’s law etc etc.
The generation time has to be really short because during the iteration cycle of an analysis you’re typically building a pipeline many many times in a single day. You may be adding or removing dependencies each time. Time spent waiting for things to build can rapidly become annoying, and that annoyance inspires hacks that undermine everything.
Anyway I’m happy to report success. capsule::capshot() can tick all the items I listed off in 1.5 - 2 seconds on my current project which is quite mature and laden with dependencies (~ 200 recursive deps). You give it paths to files containing your dependencies (typically a single file for me), and you get back a lockfile, built against the current .libPaths().
So you’ve likely never heard of {capsule} (although it does have its fans). It’s a kind of reimagining of the {renv} workflow for my team. It actually uses {renv} under the hood. The main point of difference is that it’s a lazy workflow. You don’t typically work out of a local library. You do that only when picking something up that’s been on the shelf for a long time, or putting something “into production” - i.e. running unsupervised somewhere.
The laziness has several advantages: You get no interaction with personal dev setups. RStudio, VSCode, Emacs, Addin packages etc… none of that needs to go anywhere near the lockfile. It’s also an easy sell. There’s 2 commands you absolutely need to know and they have obvious names: capsule::create() and capsule::run().
Some cool opportunities get opened up by the always-make-a-lockfile workflow. If we’re doing that, hopefully, we’re always committing it, and so it can become a mechanism to help nudge team-mates to keep their R libraries moving forward in step.
For example, your lockfile target could pass on building a new lockfile that would contain versions behind the current one, and send a warning to update pacakges. There’s actually machinery already in {capsule} for that, although I am still settling on the best design. I am excited to get a feel for the best practice for this kind of stuff over the next few weeks!
Are CRAN’s policies degrading #rstats package quality?
Due to one of my current projects, R developers have been sharing their frustrations with CRAN with me. There are many distrubing aspects to these stories, but one that is on loop in my brain at the moment is the systemic degradation CRAN policies are creating.
I think this degradation is slow and doesn’t impact too much on functionality, so it will be hard to spot at first. If there is a trend though, over time its corrosive nature will become sorely apparent. This is because developers have confessed to:
- removing all external links from documentation to avoid being flagged when one of those becomes a redirect.
- deleting examples from their code that were being run even though they were flagged with
\donttest. - suppressing tests on CRAN that were creating issues that could not be easily reproduced
- ditching vignettes that were struggling to build on CRAN
It’s kind of sad to imagine what the cumulative effect looks like of developers being nudged away from creating thoroughly tested works with rich interconnected explanatory documentation. To me, it’s just an odd situation to be in: where R itself contains excellent tools for this, but our package infrastructure is having a potentially out-sized influence on the utilisation of those tools.
l33t Data scientists can write #julialang to write R. They can write #haskell to write R. They can write #clojure to write R. For a long time many have been writing a half-baked version of #rstats ported to #python. Life’s a bit simpler if you Just. Write. R. Though?
Just say no to !important
Subtweeting an out of control hairy yak that has raised 2 gh issues, 1 stack overflow question, and 1 package update, and eaten most of my day.
Any old folder can be a git remote
Becasuse of GitHub I am not that used to thinking of git as a peer to peer decentralised version control system - despite the fact I know this theoretically. An upshot of this property that any folder that you have access to can act as a remote.
This came in handy today, rigging up a way to deploy code to a server that has very limited connectivity to the outside world.
First I copied my local copy over to the server.
Then on my workstation I added the folder as a remote:
git remote add prod \\analytics\blah\project_name
Then I can fetch that remote to get the branch metadata:
git fetch prod
after which I can push to it
git push prod
Well sort of. Initally I got this error:
git push prod
Enumerating objects: 18, done.
Counting objects: 100% (18/18), done.
Delta compression using up to 8 threads
Compressing objects: 100% (10/10), done.
Writing objects: 100% (11/11), 1.37 KiB | 467.00 KiB/s, done.
Total 11 (delta 6), reused 0 (delta 0), pack-reused 0
remote: Checking connectivity: 11, done.
remote: error: refusing to update checked out branch: refs/heads/main
remote: error: By default, updating the current branch in a non-bare repository
remote: is denied, because it will make the index and work tree inconsistent
remote: with what you pushed, and will require 'git reset --hard' to match
remote: the work tree to HEAD.
remote:
remote: You can set the 'receive.denyCurrentBranch' configuration variable
remote: to 'ignore' or 'warn' in the remote repository to allow pushing into
remote: its current branch; however, this is not recommended unless you
remote: arranged to update its work tree to match what you pushed in some
remote: other way.
remote:
remote: To squelch this message and still keep the default behaviour, set
remote: 'receive.denyCurrentBranch' configuration variable to 'refuse'.
To \\analytics\blah\project_name
! [remote rejected] main -> main (branch is currently checked out)
error: failed to push some refs to '\\analytics\blah\project_name
Git refused to accept my commits. The issue it is warning me about is that if I did push commits onto the main branch, the HEAD pointer in the copy on the server is not updated. So it would need to be updated by running git reset in the server’s copy.
This can be fixed by running this command on my local machine:
git config --global receive.denyCurrentBranch "updateInstead"
So now when I try to push commits onto the current branch in the server’s copy it will automatically update the HEAD, provided there is no other uncommited changes hanging out in the working tree. RAD.
So when @github Copilot drops a line of code into my project it’s also going to drop in 200 million LICENSE files and attributions right? RIGHT?