Are you Data Scientists or Software Developers?!
I think the best Data Scientists are both.
This little exchange was a spicy first question I got after walking another state agency through some of our internal travel time estimation tooling back at Queensland Fire and Emergency Services. And I’ve only come to believe it more since.
In my recent talk ‘Really Useful Engines’ I rabbited on about how effective data science teams must necessarily engineer a domain specific capability layer of software functions or packages that become a force multiplier. The simple becomes trivial, and the hard becomes tractable. This makes headroom for the development of more capabilities still. A virtuous cycle. It’s either that or get snared in a quagmire of copy-pasta code tech debt.
This post is about what that looks like, and how it can be made better with good data science tooling (or not).
What it looks like
On the one hand, you’re building data analysis pipelines. Do enough of this and you begin to recognise common patterns, or pine for certain tools to make your labour more efficient. On the other hand, you’re realising these ideas as software packages. If you’re lucky, your boss may give you clearly marked out time to do both separately. Even so, it won’t be enough. And what happens when there are bugs? You suddenly need to fix a tool so the pipeline can work. In reality, you’re frequently context switching between working on your pipelines, and underpinning them with your own tooling.
So in any one day you might work across a handful ‘projects’ - that is discrete codebases, almost certainly backed by separate git repositories. If you’re an #rstats user you probably use RStudio. So that means you have a separate RStudio instance for each project and alt-tab between. I mean I know there’s some kind of button in the corner that can switch between different projects now, but that’s even worse than alt-tab because R session state is not preserved.
Apparently, the alt-tab workflow first appeared in Windows in 1987. I want to say that’s old and tired, but I am slightly older and probably more tired.
For a long time I did it this way in VSCode for #rstats too. One tip I picked up that made alt-tab slightly less painful was the Peacock extenstion which allows you to colour your many VSCode windows distinctly to make it easy to land on the right one.
How it can be better
VSCode has a concept called ‘Workspaces’. These are a collection of projects you work on in concert. To make a workspace there’s a command you can call from the command palette, ‘Add folder to workspace’:

Fair warning: In just a sec I am going to run through a scenario that may overheat your brain if you’ve been using RStudio for a long time. So before that here are some cool things you get by setting up your pipelines and supporting packages in a workspace:
Quickly jump between files in separate projects
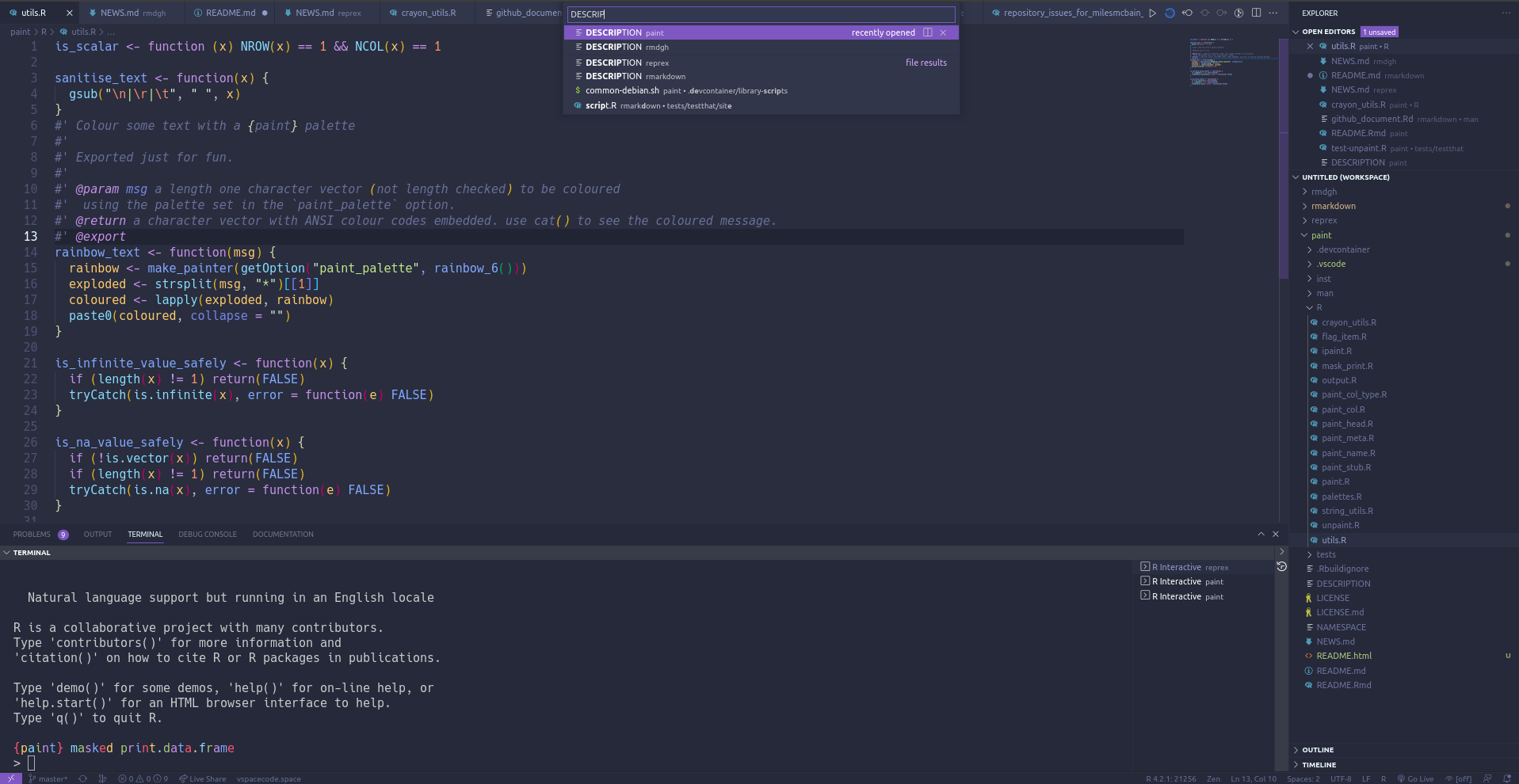
Search across all projects in the workspace
Forget where something lives? Just search it! Looking for references to some function you’re about to refactor? Just search it!
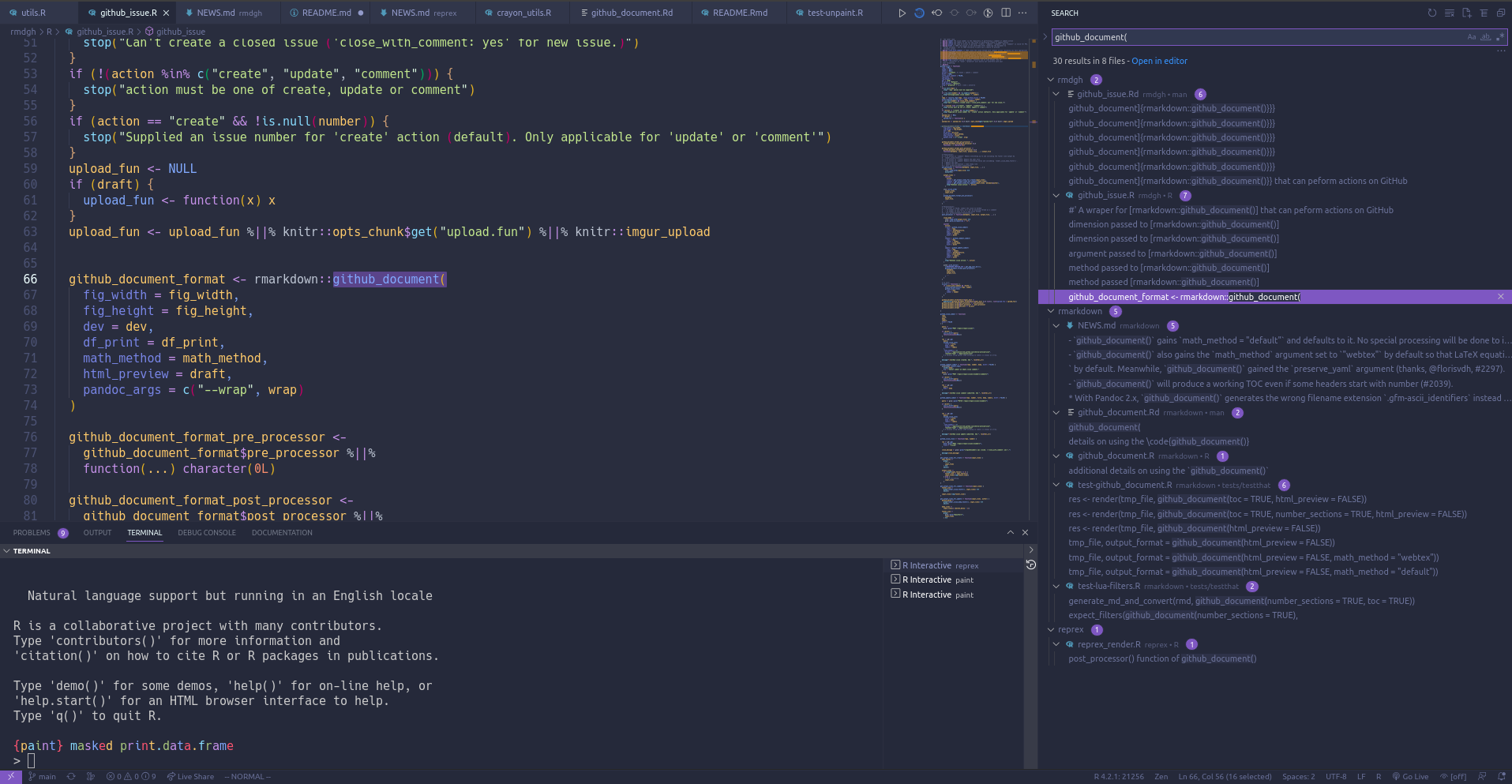
Let’s melt you
Warming up: In VScode you’re not tied to a single R session. You can have as many as you like, and these can be associated with any project in the workspace. So it’s possible to have something like this next screenshot - where you have two separate code files from two separate projects open simultaneously, running code against two simultaneously open R terminals:
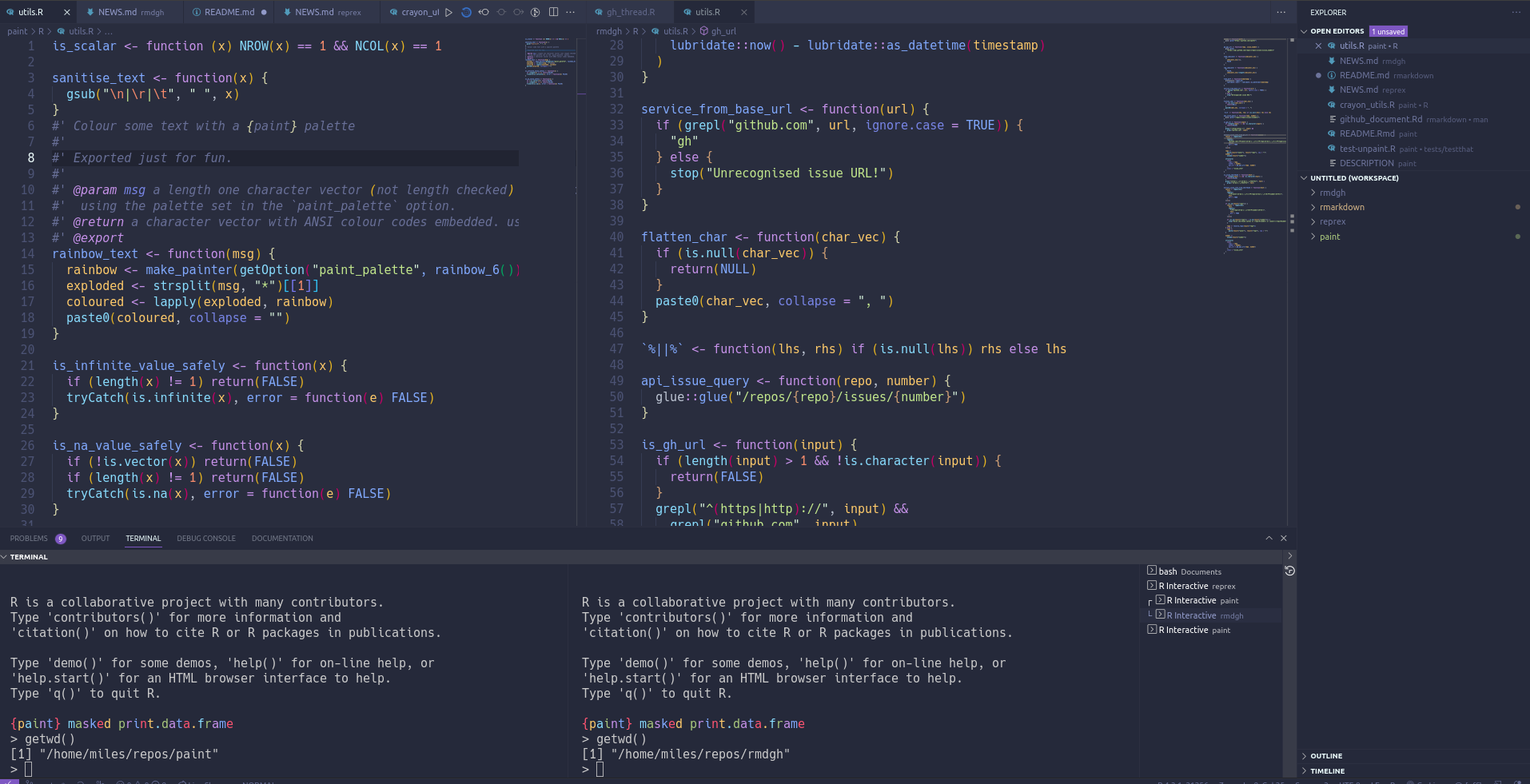
My Boss and I paired with a setup like this just last week, to work through the differences between two similar script files.
So that’s cool but kind of niche, right?
Okay so let’s imagine you’re working on pipeline, and during the course of this work you discover some R code in package that is misbehaving, in this case with an error. Of course pipeline and package are both projects in your workspace.
You narrow in on the problem with recover or debugonce interactively in an R terminal for pipeline. Which means you have an interactive context that contains data with which you can reproduce the bug, and code you can tinker with. So next you put together a reprex, and file an issue, open up the package project in a separate RStudio instance… OH NO YOU DON’T.
Next you search for the offending function in your workspace. You jump to the file in package that holds its code. You run the code in that file against the interactive context you have in pipeline’s R terminal to debug the code, making the necessary changes DIRECTLY IN THE SOURCE FILE in package, and testing them against the data in pipeline’s R terminal as you go (Look mum, no reprex!).
When you’re happy with the changes you fire up a new R terminal for package using the ‘Create R terminal’ command. You run your {devtools} stuff, maybe drop in a test, bump the version, commit to the git repo. You switch back to the pipeline terminal, drop out of debug, run remotes::install() to get the updated package, and then tar_make() (I assume) to run the now working pipeline.
The trick that makes this possible, in case it got buried, is that you can send code from any project file to any R terminal. The target terminal is the last one that had focus. This can get a bit confusing at first, and you can disable it (kind of), but I think the speed I get from it has been worth training myself to deal with it.
Conclusion
I described a context swtiching workflow based on VSCode workspaces that enables simultaneous tool-use and tool building. I enjoy it, but I am not yet fully satisfied. The terminal selection being driven by last focused means you have to get quick with your hot-keys to jump between source panes and active terminals. I can’t help but feel that if this workflow were designed end to end for this kind of data science work, this could be made even more quick and pleasant to use. A great contribution someone could make to the VSCode extension! (Or RStudio)